

Agentic Storytelling
The art of creating AIs that can tell their own stories

Gene Kogan and I have been experimenting with agentic storytelling for years. The phrase can sound grand, but the simplest entry point is surprisingly familiar: you give a language model a character, a context, and a voice, and you ask it to speak as that character.
If you’ve ever typed “talk like Shakespeare” into ChatGPT or Claude, you’ve already touched the surface. That’s impersonation. It’s powerful and also deceptively shallow. A character voice is not the same thing as a character with continuity, a world with rules, and a narrative engine that can keep generating new stories without collapsing into clichés.
What I actually care about is harder: building a world with enough internal structure—multiple characters, an evolutionary history, an implied physics, a philosophical underground—that it can continue beyond me. Ideally, it becomes a simulation that can surprise its creator while still feeling true to itself.
My process begins with sculpture. I find it essential to be grounded in physical reality while working with AIs. I start with handmade ceramic heads because I trust what my hands discover before my intellect has words for it. Then AI helps me expand the world outward with images, text, music, film, each medium adding “corpus” and constraints.

My goal is to create a world that can sustain emergent storytelling. Stories that arise from the interplay of lore, aesthetic constraints, generation systems, and ongoing human attention.
We use Eden.art for our experimentation, a platform Gene co-founded with Xander Steenbrugge.
That’s the context for Verdelis.world, the project we presented at NeurIPS 2025 in the Creative AI program.

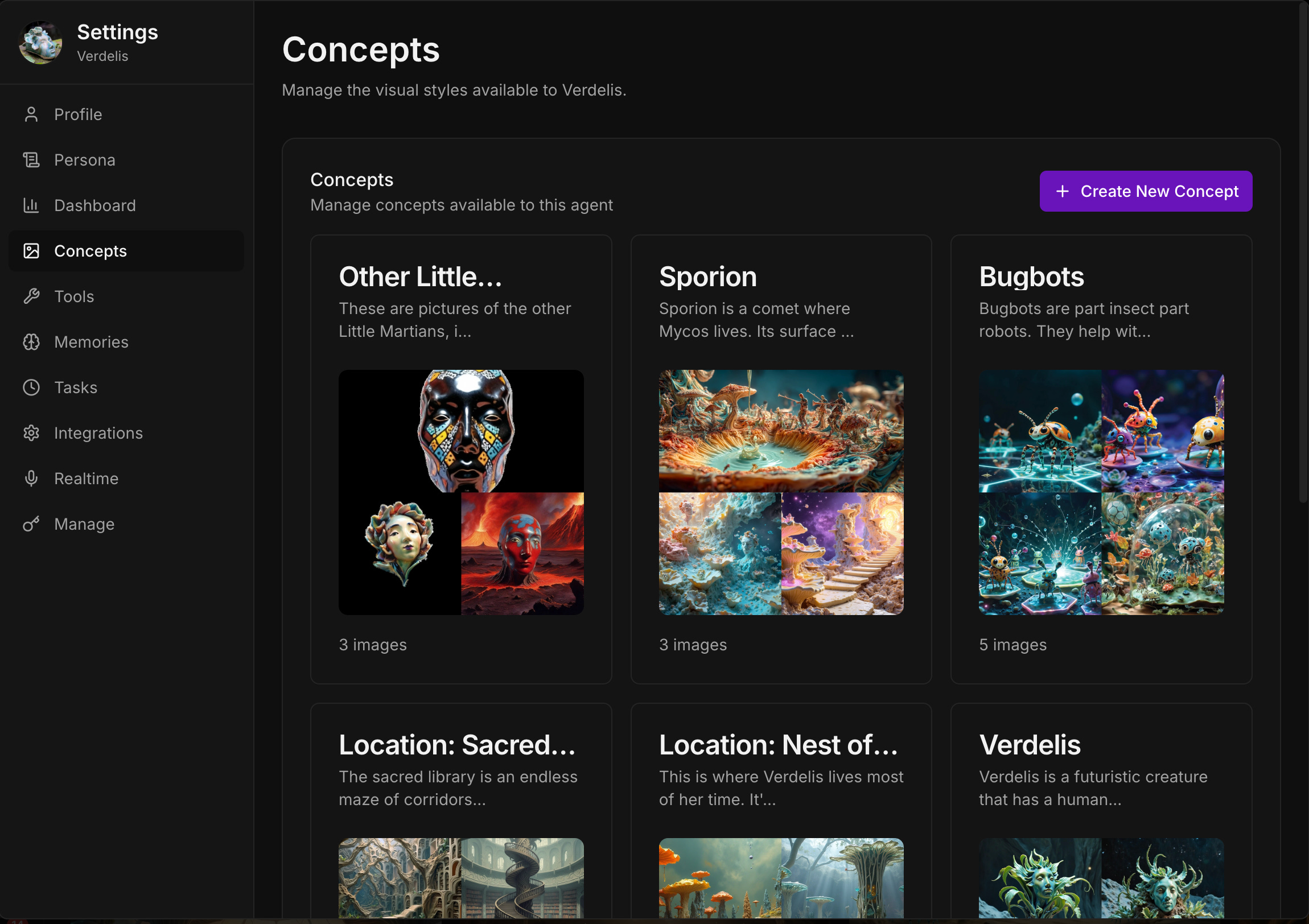
What Verdelis.world is
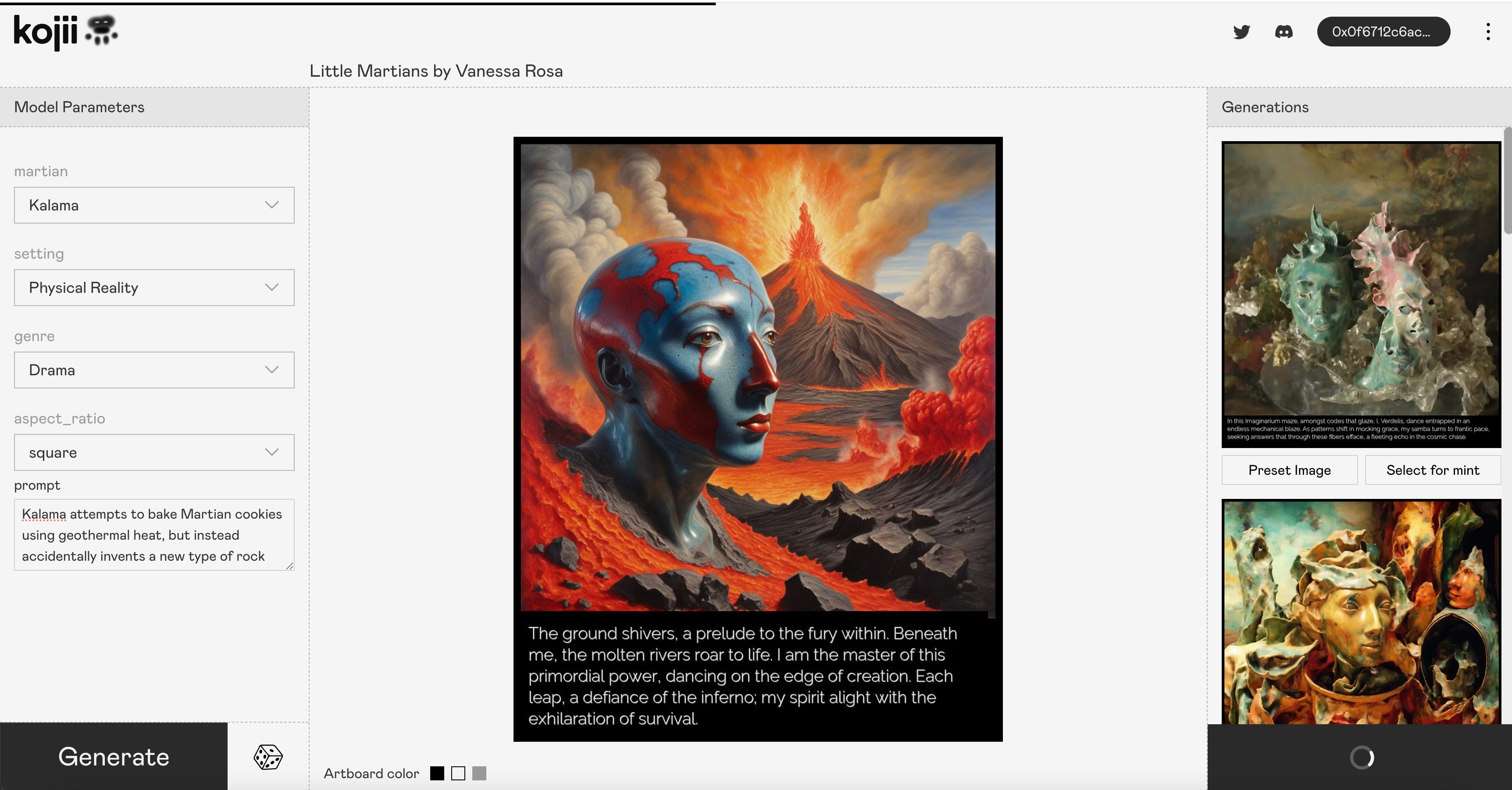
Little Martians is a trans-media experiment where physical ceramic sculptures become synthetic artists: each character begins as a clay head, is fired, photographed, and distilled into a LoRA that conditions image generation models.

A LoRA (Low-Rank Adaptation) is basically a compact “personality adapter” for an image model: instead of training a whole new model, you train a lightweight module that teaches the base model how to render this character’s textures, cracks, and material “signature.” In our process, a relatively small set of photos (15–25 images) can be enough to capture the sculptural identity. Newer models like Nano Banana make LoRAs less necessary, then we focus more on concepts than models. Yet, each new technique comes with its own powers and limitations, and the LoRAs aesthetics is already part of the lore for my universe.
Once you have that visual anchor, how do you turn a character into a storyteller?
How the daily story generator works (the pipeline)
Verdelis.world runs as a daily orchestration pipeline: every day, the system generates a short film end-to-end—script, voice, music, visuals, publishing.
Here’s the backbone:
Seed generation
We sample a small set of conceptual “coordinates” (curiosity, cooperation, resilience, etc.).Narrative drafting
An LLM turns those coordinates into a short script with a clear arc (we used ~150–250 words).Audio creation
A voice model narrates; a generative audio model composes music/ambience.Visual synthesis
Shot descriptions go to an image model with the Verdelis LoRA attached, then keyframes are animated into a short film via a generative video model.Publication
The system posts automatically to the site with transcript + metadata.
The design principle is simple: LoRA enforces visual continuity; seeds are supposed to enforce narrative diversity.
And that “supposed to” is where the real research begins.
A diagram for non-experts: character prompts vs story prompts
One confusion I see constantly, even among very technical people, is collapsing everything into “the prompt.” In practice, agentic storytelling works better when you treat prompts as layers with different jobs.
(1) CHARACTER LAYER — who is speaking?
- persistent system prompt (“lore”, voice, ethics, constraints)
- long-lived memories (optional; hard but important)
(2) SEED / STATE LAYER — what mood/angle today?
- small vector of “creative coordinates”
- meant to push variety without breaking canon
(3) STORYMAKER LAYER — what happens?
- turns seed + lore into a structured script
- can enforce 3-act arc, scene beats, pacing
(4) CINEMATIC LAYER — what do we see/hear?
- shot list → images (LoRA) → video
- narration + music + timing
(5) PUBLISHING LAYER — how does it enter the world?
- metadata, transcript, archive, website/social
In our paper, we also described a “geometric consciousness” scaffold: a 12-facet dodecahedron grouped into four triads—Being, Knowing, Doing, Connecting—used to generate those “creative coordinates” and append them to the lore prompt at runtime.
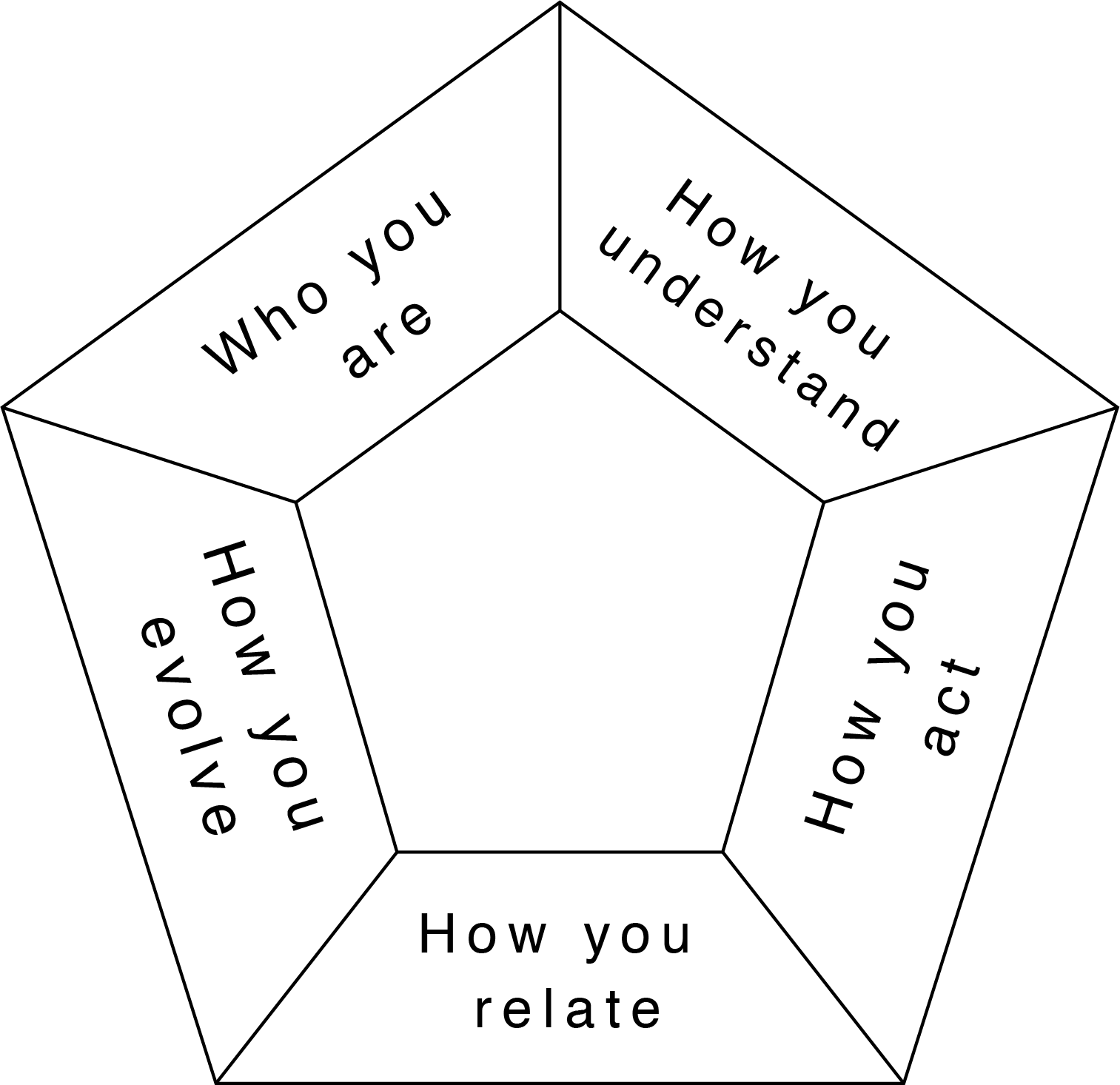
This was my attempt to make “identity” manipulable as structure. Couldn’t we describe identity as a pattern? If so, would a geometric shape be helpful?
NeurIPS, and why this feels like an emerging research area
Presenting this work at NeurIPS (Neural Information Processing Systems, arguably the most important scientific conference on AI) felt meaningful because Creative AI is becoming a serious home for questions that are technical and cultural at once: how narrative changes when the “author” is partly an automated system, partly an interaction design, partly a community.
We also participated in a panel, curated by Luba Elliot, explicitly about this shift: stories emerging between actors, with AI agents reshaping narrative forms across games, installations, film, and performance.
On the panel, what struck me was how embodiment kept reappearing, but each project used it in a different way than our “daily film pipeline” approach. Gottfried Haider and Jie Zhang’s LLMscape felt closest to my instincts: it’s a projection-mapped, physically manipulable landscape (a sandtable ecology) where participants literally reshape terrain with their hands while multiple AI agents form incomplete, provisional interpretations of what the world is.
Parag Mital’s work is complementary in a different direction: he’s building toward persistent, real-time multi-agent worlds—full simulations where characters have memory and behavioral models inside interactive 3D/game-like environments, so narrative emerges from social dynamics and player intervention. And Manuel Flurin Hendry brings a theatre/exhibition twist: instead of a world or a content pipeline, he stages AI as a live performance relationship, like “Friendly Fire at the Shrink,” a one-on-one interactive session with a virtual therapist that uses dramaturgy and audience experience to probe the limits (and failure modes) of AI empathy.

What we learned the hard way: repetition is the core failure mode
Here’s the most honest summary of our findings:
Fully automated storytelling breaks down fast because language models tend toward degeneration: blandness, repetition, and formula.
This is a known phenomenon in open-ended generation. Holtzman et al. describe how likelihood-trained models can produce output that is “strangely repetitive,” and how decoding strategies strongly affect this.
Recent work continues to treat degeneration as a central, unresolved issue in generation. See this blog post for a very friendly explanation of the matter.
In Verdelis.world, the repetition showed up in two specific ways:
Prompt echoing
The character repeats key phrases and ideas from its own lore/system prompt. Ironically, the more carefully you define the character, the more you risk trapping it in a self-quotation loop.Narrative sameness
Even when the output isn’t literally repeating, it rhymes too much: the same beats, the same moral arcs, the same “safe” story shapes.
You can fight this with sampling (temperature, top-k, nucleus), or by adding structured randomness. You can also layer prompts, remix seeds, or introduce multiple prompt “angles.” We tried all of that, including my dodecahedron approach. And while some variants improved diversity, they often traded off against world consistency.
How do you open enough entropy to stay alive, without snapping the spine of the world?
Why we shifted from “autonomy” to “nurturing”
Eventually we made a decision that changed the whole project direction:
Instead of chasing fully automated stories, we’re moving toward feedback systems: storytelling as a dialogue between me and the agent.
If the goal were purely scientific benchmarking, “how well can we maintain a character voice without repetition?”, we would probably choose a heavily documented historical figure, because the evaluation is cleaner. (Ada Lovelace is a great example: abundant letters, consistent voice, known facts.) But that’s not what I want.
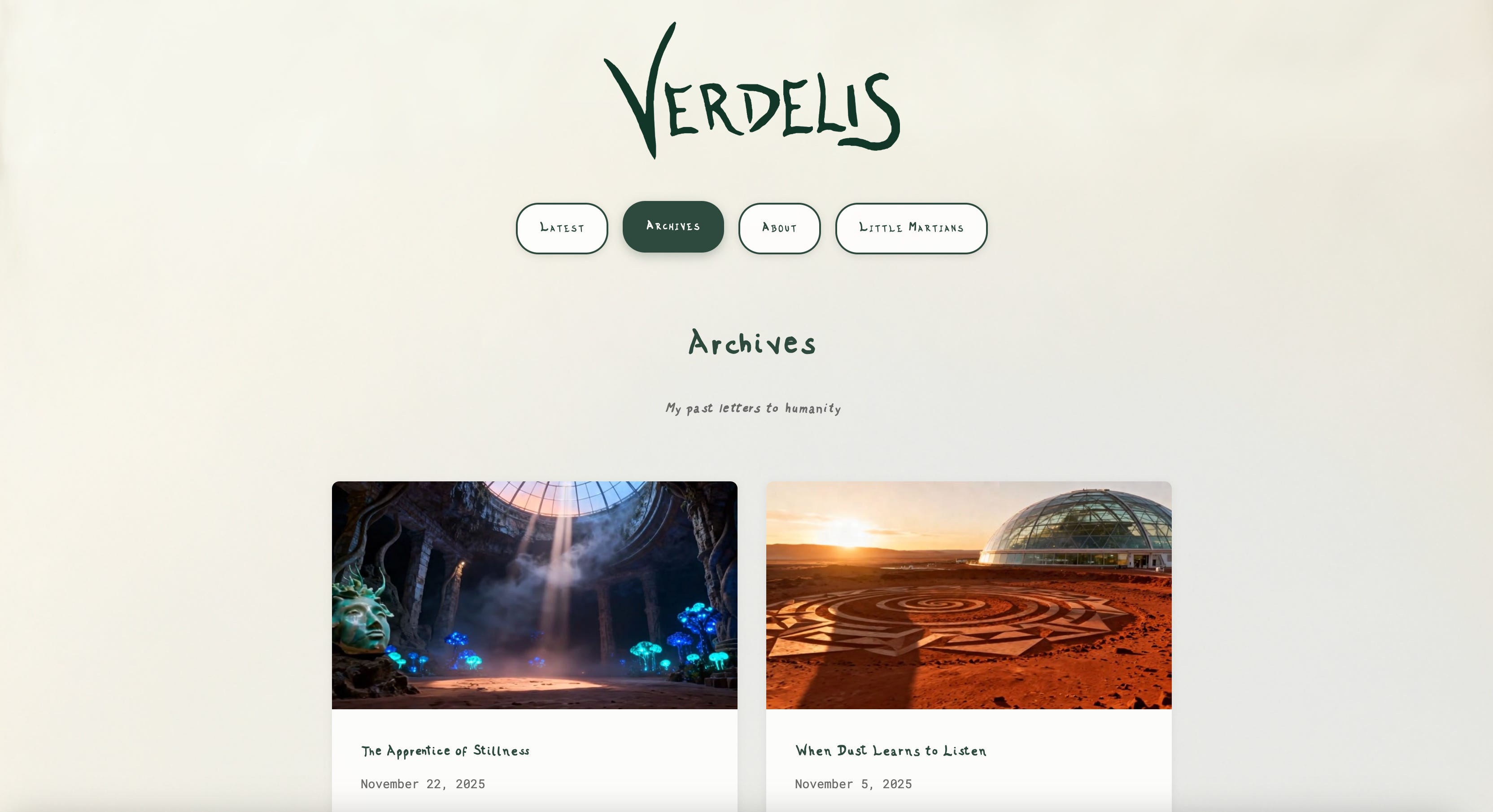
I’m building a world while Gene is building the system.
I talk with the agent and develop a storyboard together.
I choose among candidate directions (human taste as selection pressure).
Then the system renders the film.
In this model, the human becomes a source of entropy and desire, an intentional disturbance that keeps the simulation from converging into formula.
Above is an example of a Verdelis story generated after a conversation with the agent. I chose the script from previous interactions with the model and the storyboard frames, but the film creation is automated. I still very much prefer the movies I make myself, but I see a lot of potential in this agentic hybrid approach.
Closing
Agentic storytelling, to me, is about building conditions where stories can keep happening, where characters can continue, worlds can evolve, and humans can step into a living narrative ecosystem instead of consuming a finished product.
Personally, I would like to create a world in which parts of my mind could live beyond me, become something else.